

Daily bit(e) of C++ | Tech debt is bad, m'kay?!
Daily bit(e) of C++ #41, How to talk about technical debt with non-technical leaders.


Today we will take a bit of departure from the very focused technical topics and talk about a general Software Engineering topic: technical debt.
Talking about technical debt can be very hard, as it is nontrivial to define and identify its impacts on business performance.
So often, especially during hard times like the ones we are going through, the discussion boils down to the following:
Engineer: Tech debt is bad, m’kay?!
Manager: Don’t care, do it anyway!
Back to the basics
When dealing with fuzzy or hard-to-define topics, it’s worth returning to the basics.
From a business perspective, a Software Engineer is a value amplifier. Money goes in, and value comes out.
The produced value can take many forms:
it can be software directly sold to customers
working on featuresit can be money saving
optimising the cloud bill by improving the performance of servicesit can be money generation
improving algorithms that serve people more relevant productsit can be team amplification
mentoring younger Engineers that then produce more value by themselves
If we accept this abstraction, we can reframe technical debt as a source of overhead.
Meaning that with higher technical debt, you either need to put more money in (i.e. more time) or, put another way, for the same amount of money, you will get less value from each of your Software Engineers.
An important benefit of this abstraction is that it is also understandable to business leaders as it relates technical debt to cost.
We have established an abstraction, but we still need to determine how to measure technical debt.
Measuring technical debt
The first step before attempting any improvement is always to establish a metric. Otherwise, we would never know what kind of impact (if any) our efforts have.
Trying to measure technical debt directly is a fool’s errand, so let’s focus on a suitable proxy metric instead. Our abstraction equates technical debt with overhead, so let’s use that as our proxy.
If we measure the ratio between productive use of time and overhead activities, we should see this ratio improve as we address technical debt.
What is overhead anyway?
This, of course, creates a second problem. How do we determine which activities are overhead and which are a productive use of time?
Some activities are obvious overhead caused by technical debt, such as root-causing issues or trying to understand old code.
However, some activities are not so clear-cut. For example, poor onboarding can be a significant source of technical debt, but do you count onboarding itself as overhead?
Luckily, if we measure the ratio between productive and unproductive time, where exactly we draw the line isn’t that important. A good start is to pick only the core activities (working on design and code) as productive.
This will capture other “debt” as overhead, notably institutional debt in the form of excessive meetings or cumbersome procedures. And while that means that we are not measuring strictly technical debt, that is not a bad thing.
The second type of variance will arise from each person having different standards regarding what they consider overhead and how they measure and record the time spent. But, again, the actual system doesn’t matter as long as everyone is consistent with their approach.
The goal here isn’t to measure the actual amount of waste but to see the impact of systemic changes on the ratio between productive and unproductive use of time.
Beware the plateau of despair
One trap an Engineering organisation can fall into is unmanaged technical debt.
Because technical debt is compounding, it is relatively easy to reach a point where one-off projects to address technical debt will not produce tangible results. The financial equivalent would be paying off part of your debt while your monthly income remains below your monthly interest.
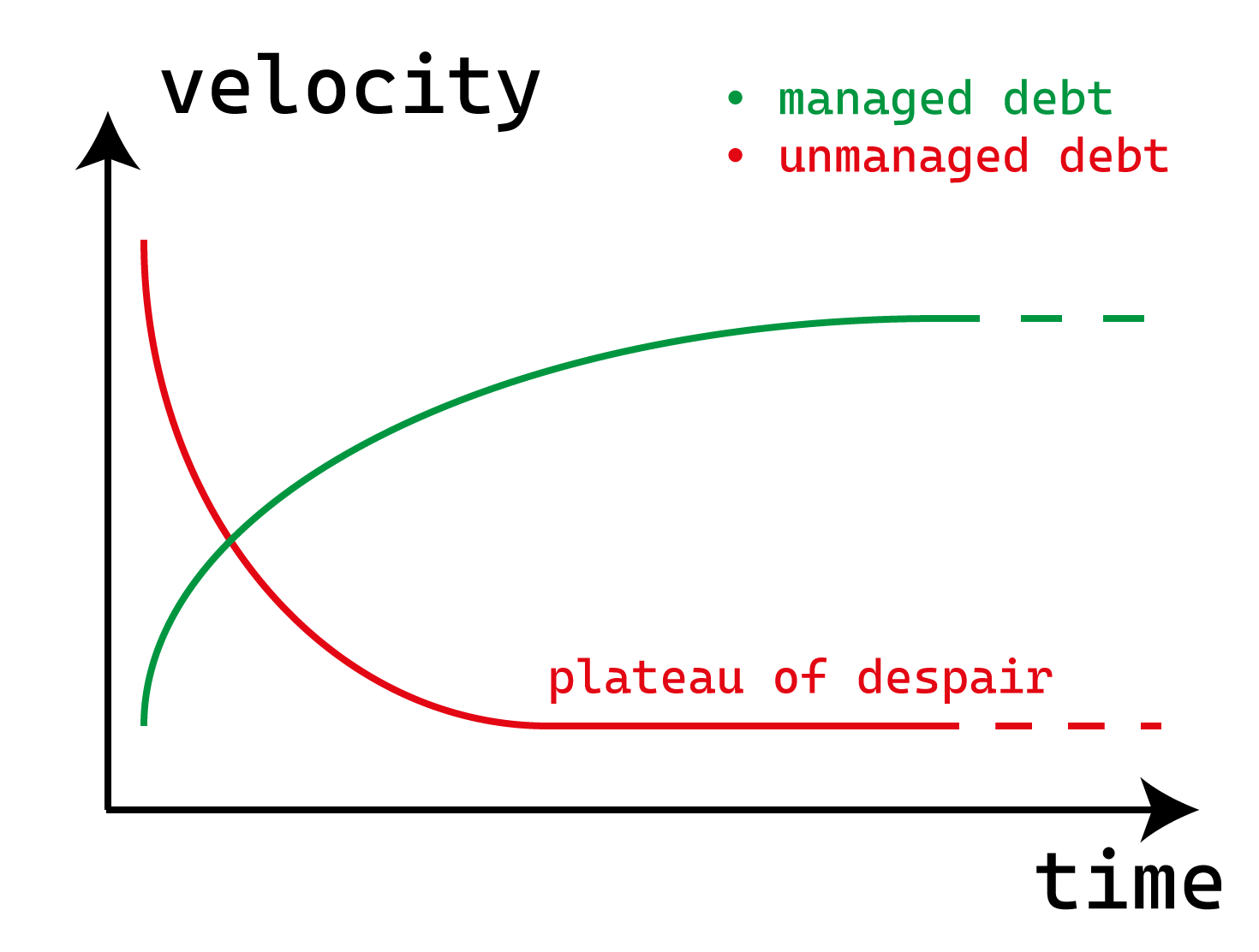
In such a situation, addressing technical debt might seem pointless (especially to management).
So how do you get out of the plateau of despair?
Addressing technical debt
Finally, let’s discuss some high-level approaches to systematically addressing technical debt.
The basic idea behind all of these approaches is that they are also compounding, aiming at prevention (decreasing the rate at which we generate technical debt) while at the same time addressing some of the existing technical debt.
Global automated cleanups
Automated tools, such as clang-tidy auto-fixes, can address straightforward problems. This isn’t necessarily risk-free (especially in a codebase with insufficient test coverage), but it has the benefit of being fast and fully automated.
At a minimum, all code should have the same formatting and naming style. The formatting can be enforced using clang-format, and naming can be enforced using clang-tidy.
Such solutions can be deployed as part of the code commit workflow, automatically fixing each commit before it is sent for code review.
Gating
One of the most effective tools is gating. For example, consider the following situation: your codebase is in a bad state, doesn’t have sufficient test coverage, and produces many warnings, even with the basic set of flags.
Addressing this problem globally would probably take forever and would likely fail. So instead, we can use the gating approach, requiring that any new (or changed) code has 100% delta test coverage and cannot introduce new warnings.
For some metrics, such an approach can be gated automatically (such as delta test coverage), and some metrics will require a semi-automated approach using code review.
Establishing gates even for problems currently not present in the code base is typically a worthwhile effort as it prevents any future instances of that type of problem (e.g. deploying address and thread sanitisers while testing, even when the current code base compiles and runs cleanly).
Peeling the onion
For some problems, it is worthwhile to sit down and invest in a focused effort to address this one specific problem, notably if this problem is preventing you from deploying a gate.
Such efforts can quickly spiral out of control, so it is crucial to always focus on a single problem (e.g. cleaning up a single warning) or only focus on one portion of the code base (e.g. cleaning up address sanitiser issues in a single component).
Once you have peeled the onion, do not forget to establish a gate so this problem doesn’t happen again.
Pruning and grafting
The best code is often the code that doesn’t exist. In particular, in older codebases, there is a good chance for dead branches that can be pruned from the codebase. Deleted code doesn’t need tests and cannot have bugs.
On top of deleting code, replacing code is also a great option. Is there a library with a compatible license that you can use to replace a portion of your codebase?
Answering that will probably not be clear-cut. A 3rd party library won’t be hyper-optimised for your use case, so you will need to weigh the benefit of getting rid of code against the downsides.
Conclusion
Framing technical debt as a source of overhead is a context understandable to business leaders as it spells out the impact on the business.
It also allows us to establish a simple metric based on overall time spent on overhead activities. Because the goal is to observe an improvement in the ratio, there is no need for precise measurement (each team member being reasonably consistent with their labelling of what they consider overhead is good enough).
Once the metric is established, systemic solutions focusing on prevention can slowly move the codebase to a better state. Resulting in lower overhead, which will then demonstrate itself in the metric.